在搜索引擎蜘蛛系统中,待爬取URL队列是很关键的部分,需要蜘蛛爬取的网页URL在其中顺序排列,形成一个队列结构,调度程序每次从队列头取出某个URL,发送给网页下载器页面内容,每个新下载的页面包含的URL会追加到待爬取URL队列的末尾,如此形成循环,整个爬虫系统可以说是由这个队列驱动运转的。同样我们的网站每天都要经过这样一个队列,让搜索引擎进行爬取的。
那么待爬取URL队列中的页面URL 的排列顺序是如何来确定的呢?上面我们说了将新下载页面中的包含的链接追加到队列尾部,这固然是一种确定队列URL顺序的方法,但并非唯一的手段,事实上,还可以采纳很多其他技术来实现,将队列中待爬取的URL进行排序。那么究竟搜索引擎蜘蛛是按照什么样的策略进行的爬取呢?以下我们来进行更深入的分析吧。
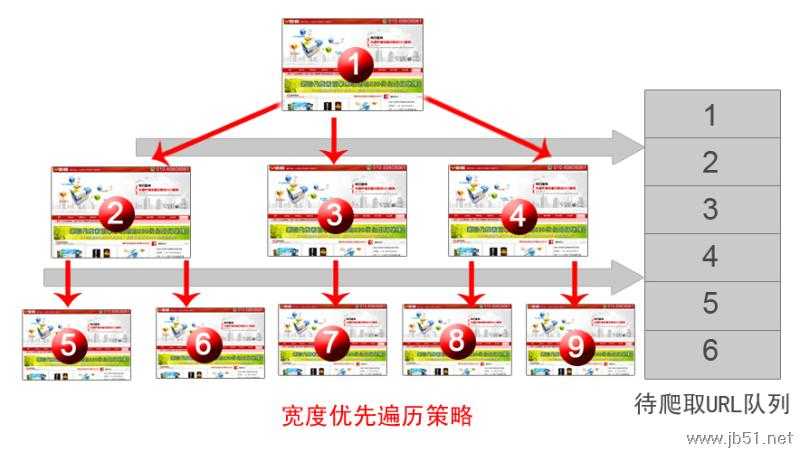
第一、宽度优化遍历策略
宽度优化遍历是一种非常简单直观且历史很悠久的遍历方法,在搜索引擎爬虫一出现就开始采用了。新提出的抓取策略往往会将这种方法作为比较基准,但应该注意到的是,这种策略也是一种相当强悍的方法,很多新方法实际效果不见昨比宽度优化遍历策略好,所以至今这种方法也是很多实际爬虫系统优先采用的爬取策略。网页爬取顺序基本是按照网页的重要性排序的。之所以如此,有研究人员认为,如果某个网页包含很多入链,那么更有可能被宽度优化遍历策略早早爬到,而入链这个数从侧面体现了网页的重要性,即实际上宽度优化遍历策略隐含了一些网页优化级假设。
第二、非完全pagerank策略
PageRank是一种著名的链接分析算法,可以用来衡量网页的重要性。很自然地,可以想到用PageRank的思想来对URL优化级进行排序。但是这里有个问题,PageRank是个全局性算法,也就是说当所有网页下载完成后,其计算结果才是可靠的,而爬虫的目的就是去下载网页,在运行过程中只能看到一部分页面,所以在爬取阶段的网页是无法获得可靠的PageRank得分的。对于已经下载的网页,加上待爬取的URL队列中的一URL一起,形成网页集合,在此集合内进行PageRank计算,计算完成之后,将待爬取URL队列里的网页按照按照PageRank得分由高低排序,形成的序列就是爬虫接下来应该依次爬取的URL列表。这也是为何称之为“非完全PageRank”的原因,。
第三、OPIC策略( Online Page Importance Computation)
OPIC的字面含义是“在线页面重要性计算”,可以将其看做是一种改进的PageRank算法。在算法开始之前,每个互联网页面都给予相同的现金,每当下载了某个页面P后,P就将自己拥有的现金平均分配给页面中包含的链接页面,氢自己的现金清空。而对于待爬取URL队列中的网页,则根据其手头拥有的现金金额多少排序,优先下载现金最充裕的网页,OPIC从大的框架上与PageRank思路基本一致,区别在于:PageRank每次需要迭代计算,而OPIC策略不需要迭代过程。所以计算速度远远快与PageRank,适合实时 计算使用。同时,PageRank,在计算时,存在向无链接关系网页的远程跳转过程,而OPIC没有这一计算因子。实验结果表明,OPIC是较好的重要性衡量策略,效果略优于宽度优化遍历策略。
第四、大站优化策略
大部优化策略思路很直接:以网站为单位来选题网页重要性,对于待爬取URL队列中的网页根据所属网站归类,如果哪个网站等待下载的页面最多,则优化先下载这些链接,其本质思想倾向于优先下载大型网站。因为大型网站往往包含更多的页面。鉴于大型网站往往是著名企业的内容,其网页质量一般较高,所以这个思路虽然简单,但是有一定依据。实验表明这个算法效果也要略优先于宽度优先遍历策略。
第五、网页更新策略
互联网的动态是其显著特征,随时都有新出现的页面,页面的内容被更改或者本来存在的页面删除。对于爬虫来说,并非将网页抓取到本地就算完成任务,也要体现出互联网这种动态性。本地下载的网页可被看做是互联网页的镜像,爬虫要尽可能保证其一致性。可以假设一种情况:某 个网页已被删除或者内容做出重大变动,而搜索引擎对此惘然无知,仍然按其旧有内容排序,将其作为搜索结果提供给用记,其用户体验度之糟糕不言而喻。所以对于已经爬取的网页,爬虫还要负责保持其内容和互联网页面内容的同步,这取决于爬虫所彩用的网页更新策略。网页更新策略的任务是要决定何时重新爬取之前已经下载过和网页,以尽可能使得本地下载网页和互联网原始页面内容保持一致。常用的网页更新策略有三种:历史参考策略,用户体验度策略和聚类抽样策略。
(1)什么是历史参考策略?
历史参考策略是最直观的一种更新策略,它建立于如下假设之上:过去频繁更新的网页,那么将来也会频繁更新,所以为了预估某个网页何时进行更新,可以通过参考其历史更新情况来做出决定。
从这一点可以看出,我们网站的更新一定要有规律的进行,这样才能让搜索引擎蜘蛛更好的来关注你的网站,把握你的网站,很多人在更新网站的时候,不知道为什么要做规律性的更新,这就是真正存在的原因。
(2)什么是用户体验度策略?
这个很明显,大家都知道。一般来说,搜索引擎用户提交查询结果后,相关的搜索结果可能成千上万,而用户没有耐心去查看排在后面的搜索结果,往往只盾前三页搜索内容,用户体验策略就是利用搜索引擎用户的这个特点来设计更新策略的。
(3)聚类抽样策略
上面介绍的两种网页更新策略严重依赖网页的历史更新信息,因为这是能够进行后续计算的基础。但在现实中为每个网页保存历史信息,搜索系统会增加 额外的负担。从另外一个角度考虑,如果是首次爬取的网页,因为没有历史信息,所以也就无法按照这两种思路去预估其更新周期,聚类抽样,策略即是为了解决上述缺点而提出的。网页一般具有一些属性,根据这些属性可以预测其更新周期,具有相信属性的网页,其更新周期也是类似的。
通过以上对搜索引擎蜘蛛的爬取过程以及爬取策略进行了简单的了解之后,你是否应该有些考虑了?试着对自己的网站进行改变了?以上的一些原因说明了搜索引擎的更新是有规律以及有章法进行的,要想更能适应搜索引擎的更新原则和蜘蛛爬取原则,我们就应该从更基础的入手去进行全面的分析和总结。
搜索引擎蜘蛛
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。